
「テストの点数が、平均点より高い人を探して」
上司にこう言われた時、あなたはどうしますか。
まず、全員の点数を合計して平均点を計算する。(例:63点)
その数字をメモする。
「63点以上の人」を探すSQLを書く。
この手順を踏んでいるなら、あなたはSQLに負けています。
二度手間です。
平均点が変わるたびに計算し直すのはクレバーとは言えません。
SQLには、この2つの作業を1回で終わらせる必殺技があります。
それが「副問い合わせ(サブクエリ)」です。
これは、SQLの中に別のSQLを埋め込む技術です。
いわば、テスト中にこっそり答えを見る「カンニング」のようなものです。
構造:カッコ()の中は先に実行される
副問い合わせの仕組みは単純です。
SQL文の中に、カッコ()で囲まれた別のSQL文が入っています。
数学の計算と同じです。
カッコの中が先に計算されます。
SELECT
*
FROM
users
WHERE
score > (ここに別のSQLを書く);データベースは、まずカッコの中のSQL(サブクエリ)を実行します。
そこで得られた結果(答え)を使って、外側のSQL(メインクエリ)を実行します。
たとえば以下のようにです。
サブクエリ: 「平均点は何点?」→「63点です」
メインクエリ: 「よし、じゃあ63点以上の奴を連れてこい」
この連携プレーが、一瞬で行われます。
具体例:平均点より高い人を探す
では、実際に書いてみましょう。
「tests」テーブルから、平均点以上の生徒を抜き出します。
SELECT
name,
score
FROM
tests
WHERE
score >= (
SELECT
AVG(score)
FROM
tests
);見てください。
WHEREの後ろに、もう一つSELECTがあります。
(SELECT AVG(score) FROM tests)が先に実行され、平均点(例えば63)が算出される。
その結果がその場に埋め込まれる。
「WHERE score >= 63」として全体の検索が走る。
あなたは「平均点が何点か」を知る必要はありません。
勝手に計算して、勝手に比較してくれます。
データが更新されて平均点が変わっても、このSQLは常に正しい結果を返し続けます。
前述の通り、平均点を求めるサブクエリが毎回実行されるからです。
複数行の罠:イコールではなくINを使うべし
サブクエリが返す答えが「1つ」とは限りません。
「数学が80点以上の人の名前リスト」のように、結果が複数になることもあります。
この時、=(イコール)を使うとエラーになります。
イコールは「1対1」の比較にしか使えないからです。
「Aさんの点数」と「Bさん、Cさん、Dさん」をイコールで結ぶことはできません。
結果が複数になる場合は、INを使います。
-- 数学(subject_id=1)が80点以上の人が所属するクラスのメンバー全員
SELECT
*
FROM
students
WHERE
class_id IN (
SELECT
class_id
FROM
tests
WHERE
subject_id = 1
AND score >= 80
);カッコの中のサブクエリは、「1,3,5」のようなリストを返します)(1組、3組、5組というイメージ)。
それを受けて、外側のSQLは「クラスIDが、そのリストの『中に含まれる(IN)』生徒」を探します。
- 答えが1つなら: = , >, < など
- 答えが複数なら:IN
この使い分けさえ覚えれば、サブクエリは怖くありません。
動作イメージ:SQLのシミュレーション
このSQLが実際にどう動いているのか、スローモーションで見てみましょう。
まず、データを用意するSQLを以下に示します、。これらのデータがある前提とお考えください。
-- 1. 生徒テーブル(students)を作成
CREATE TABLE students (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
class_id INT
);
-- 生徒データを投入(1組、2組、3組の生徒たち)
INSERT INTO students (name, class_id) VALUES
('A君', 1),
('Bさん', 1),
('C君', 1),
('Dさん', 2),
('E君', 2),
('Fさん', 3),
('G君', 3);
-- 2. テスト結果テーブル(tests)を作成
-- ※実験しやすくするため、nameやclass_idもこのテーブルに入れています
CREATE TABLE tests (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
class_id INT,
subject_id INT, -- 1:数学, 2:英語 と仮定
score INT
);
-- テストデータを投入
INSERT INTO tests (name, class_id, subject_id, score) VALUES
('A君', 1, 1, 90), -- 1組:数学 90点(対象!)
('Bさん', 1, 1, 40), -- 1組:数学 40点
('C君', 1, 1, 100), -- 1組:数学 100点(対象!ここで1組が重複する)
('Dさん', 2, 1, 55), -- 2組:数学 55点
('E君', 2, 1, 60), -- 2組:数学 60点
('Fさん', 3, 1, 85), -- 3組:数学 85点(対象!)
('G君', 3, 1, 30); -- 3組:数学 30点Code language: SQL (Structured Query Language) (sql)データベースの中では、以下のStep 1~2の2段階が一瞬で行われています。
Step 1. 内側の「スパイ」がリストを作る
まず、カッコの中(サブクエリ)がtestsテーブルを走査します。
(SELECT class_id FROM tests WHERE subject_id = 1 AND score >= 80)「数学(ID=1)で80点以上の答案はどれだ?」
スパイは該当する答案を見つけ、その「クラスID」だけをメモして帰ってきます。
以下のように取得されるイメージです。
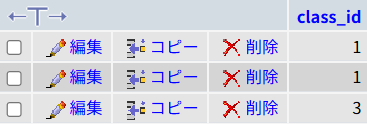
- A君(90点) → 1組
- C君(100点) → 1組
- Fさん(85点) → 3組
結果、スパイが持ち帰った報告書(リスト)は前述の通りこうなります。
→ (1, 1, 3)
「1が重複しているけれど不要ではないか。重複が無いように取得したほうがいいのではないか」とお考えになった方もいるかもしれませんが、今は気にしなくて問題ありません。
Step 2. 外側の「部隊」が突入する
次に、外側のSQL(メインクエリ)が動きます。
この時点で、SQLは魔法のように書き換わっています。
SELECT * FROM students WHERE class_id IN (1, 1, 3);あとは単純です。
studentsテーブル(生徒名簿)を見て、「1組」または「3組」に所属する(「class_id」カラムが1か3である)生徒を全員確保します。
実際に全員確保された様子が以下です。
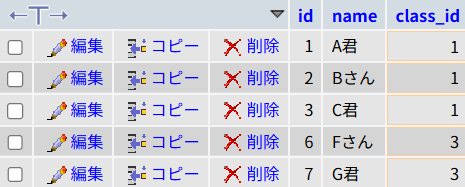
ここで重要なのは、「80点取った本人」だけでなく、「そのクラスの生徒全員」が選ばれるという点です。
「優秀な生徒がいるクラスには、何か秘密があるに違いない。クラスごと調査だ!」
サブクエリ(副問い合わせ)の説明のために用意したこのSQLですが、以上のような処理になっています。
まとめ:SQLの中にスパイを潜り込ませろ
副問い合わせ(サブクエリ)とは、SQLの内部に潜入させる「調査員」のような存在です。
メイン部隊が突入する前に、調査員(サブ)が現地に行き、必要な情報(平均点やIDリスト)を入手する。
その情報をもとに、メイン部隊が的確にデータを確保する。
この構造を理解すれば、複雑な条件もひとつのSQLで記述できます。
電卓を叩くのはやめて、計算もデータベースに丸投げしてください。
そしてスマートに怠けましょう。


コメント